近期重读《程序员的自我修养》总结程序的编译、链接、装载过程。书中的第二章《编译和链接》十分清楚地描述了编译和链接的整体工作,本文在此简要总结,算是一篇读书笔记。
gcc编译过程全貌
介绍编译过程也不能免俗,以hello world程序开始编译之旅:
1 |
|
使用gcc编译并运行hello world程序:
1 | # gcc --verbose hello.c -o hello |
上述编译过程分为四个阶段:预编译(preprocessing)、编译(compilation)、汇编(assembly)和链接(linking)。如图所示: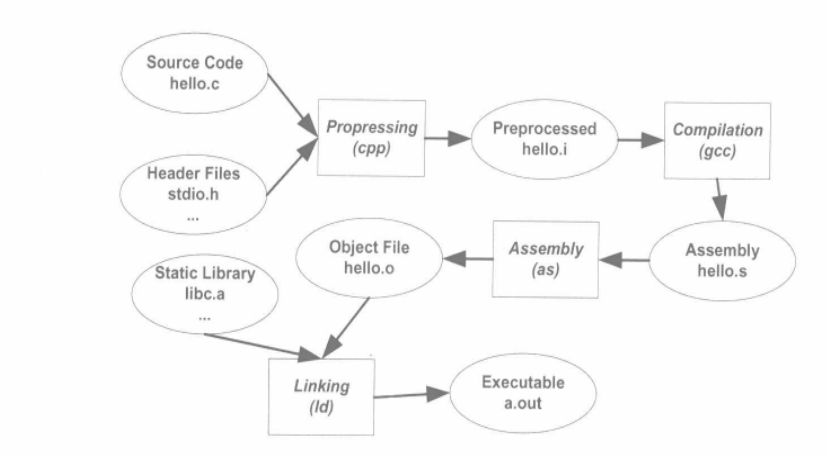
预编译(preprocessing)
预编译过程是处理源代码中以”#”开头的预编译命令,gcc的预处理命令是gcc -E或者cpp,预处理后的文件扩展名以.i结尾:
1 | # cpp hello.c > hello.i |
所有的预编译命令的处理规则如下:
- 展开所有
#define宏定义 - 处理所有条件预编译指令,如
#if、#ifdef、#elif、#else、#endif - 处理
#include预编译指令,将所有包含的头文件都插入到该预编译指令的位置,这个过程是递归的 - 删除所有的注释
//和/* */ - 添加行号和文件名标识,如
main函数上的# 3 "hello.c",以便编译器产生调试用的行号信息以及编译过程中产生告警、报错能够提示行号 - 保留所有
#pragma编译器指令,编译器会用到它
编译(compilation)
编译过程是将预处理完的文件经过一系列的词法分析、语法分析、语义分析及优化生成相应的汇编代码。gcc的编译过程相当于:
1 | # gcc -S hello.c |
汇编代码以.s后缀结尾,实际版本的gcc将预编译和编译在一个步骤中完成,上面的/usr/libexec/gcc/x86_64-redhat-linux/8/cc1程序完成这个过程。
整个编译过程可以分为6步:扫描、语法分析、语义分析、源代码优化、代码生成和目标代码优化: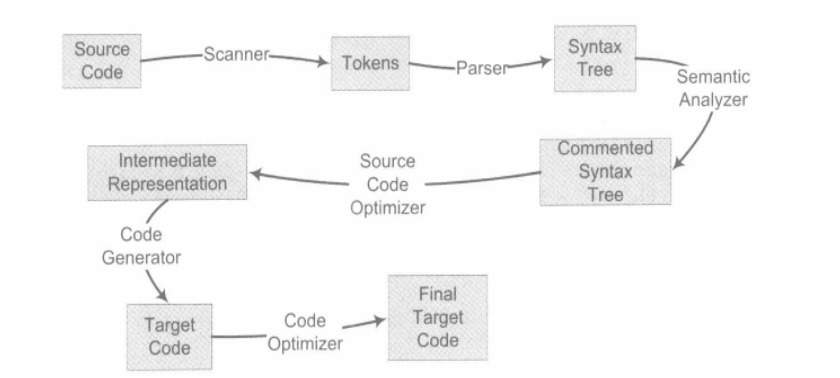
以简单程序CompilerExpression.c为例,分析其中的赋值语句的编译过程(这个程序显然没有任何意义,且未对入参进行边界检查):
1 | # cat CompilerExpression.c |
词法分析(lexical analysis)
源码首先会被词法分析器(lexical analyzer,简称lexer),也称扫描器(scanner)进行词法分析,运用一种类似有限状态机(Finite State Machine)的算法将源代码的字符序列分割成一系列记号(token)。赋值语句经过扫描后,产生了17个记号:
| 记号 | 类型 |
|---|---|
| array | 标识符 |
| [ | 左方括号 |
| index | 标识符 |
| ] | 右方括号 |
| = | 赋值 |
| ( | 左圆括号 |
| index | 标识符 |
| + | 加号 |
| 4 | 数字 |
| ) | 右圆括号 |
| * | 乘号 |
| ( | 左圆括号 |
| 2 | 数字 |
| + | 加号 |
| 6 | 数字 |
| ) | 右圆括号 |
| ; | 语句结束 |
词法分析产生的记号可以分为以下几类:
- 字面量:数字、字符、字符串等
- 操作符:算术运算符、赋值运算符等
- 分隔符:分号、括号、逗号等
- 标识符:变量名、函数名等
- 关键字:int、switch、break等
gcc支持C、C++、fortran等编程语言的编译,那么gcc内部是否为每种编程语言都实现了一个词法解析器呢?答案并非如此,flex(The Fast Lexical Analyzer)用于生成词法分析器,编译器设计者提供相应的词法规则作为输入。
以下是简单的flex词法规则文件(.l后缀):
1 | # cat simpleLex.l |
flex读取词法规则文件默认生成lex.yy.c文件,其中定义了C代码格式函数yylex()用作词法解析,该函数可以看做有限状态机。%%必须在本行最前面,即之前不允许有任何空格,flex词法文件的结构[1]:
1 | definitions |
definitions和user code参考flex官方文档,最重要的是rules,其结构如下:
1 | pattern action |
pattern不能有缩进,action必须和pattern在同一行。pattern可以是正则表达式,参考flex文档[2]。匹配模式,则会执行相应动作,action以C语言代码描述,可以使用return向yylex函数的调用者返回一个值[3]。
将lex.yy.c文件与flex运行时库链接,生成的可执行程序运行时会分析输入中出现的正则表达式,若匹配则执行相应的C代码,上面的示例会将字符串中的”good”替换为”bad”:
1 | # yum install flex-devel -y |
输入”hello good boy”会替换输出为”hello bad boy”,反汇编simpleLexer:
1 | # objdump -d simpleLexer |
simpleLexer程序调用yylex进行词法分析,该函数扫描文件(默认为标准输入),当扫描到一个完整、最长的、可以和正则表达式匹配的字符串时,则执行规则后的C代码,如果C代码中没有return语句,则执行完这些C代码之后,yylex会继续运行,开始下一轮的扫描[4]。
gcc源码中有相应的.l词法规则文件,依赖flex生成词法分析器[5]:
Similarly, when building from the source repository or snapshots, or if you modify *.l files, you need the Flex lexical analyzer generator installed. If you do not modify *.l files, releases contain the Flex-generated files and you do not need Flex installed to build them. There is still one Flex-based lexical analyzer (part of the build machinery, not of GCC itself) that is used even if you only build the C front end.
语法分析(syntactic analysis)
语法分析器(grammar parser)对扫描器产生的记号进行语法分析以产生语法树(syntax tree)。整个分析过程采用上下文无关语法(context-free grammar)的分析手段,由语法分析器产生的语法树就是以表达式(expression)为节点的树。C语言的一条语句就是一个表达式,复杂语句是多个表达式的组合。上面语句由赋值表达式、加法表达式、乘法表达式、数组表达式、括号表达式组成,形成的语法树如图所示: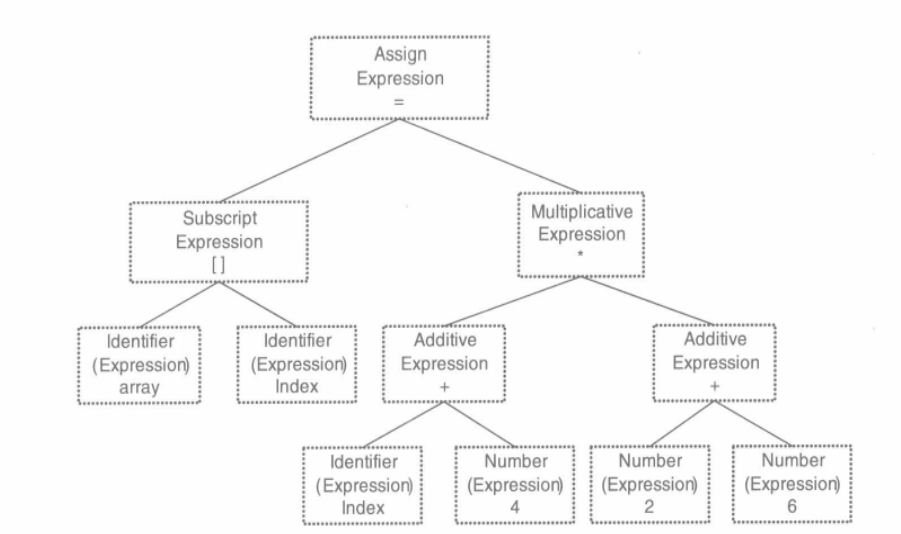
语法树构建过程中,运算符的优先级和含义已经确定下来。*在C语言中可以表示乘法运算,也可以表示取指针运算。语法分析阶段必须对这些内容进行区分,如果出现了表达式不合法,如括号不匹配、缺少操作符,编译器在语法分析阶段就报错。
同flex,gcc也是利用相应工具根据语法规则生成相应的语法分析器,而无需为每种编程语言都写一个语法分析器。yacc(Yet Another Compiler Compiler)用来生成语法解析器,被称为“编译器的编译器”,最初由AT&T的Steven C. Johnson在Unixs上实现[6],yacc已经成为POSIX标准的一部分。yacc在开源软件领域有两个替代实现:Berkeley Yacc (byacc)、GNU Bison。前者以public domain许可证发行,后者以GPL许可证发行[7],两者都兼容yacc。
语义分析(semantic analysis)
语法分析仅能够完成对表达式语法层面的分析,但它并不了解这个语句是否真的有意义。比如C语言里两个指针做乘法运算是没有意义的,但是这个语句是符合语法的。编译器所能分析的语义是静态语义(static semantic),静态语义是在编译期可以确定的语义,相对应的是动态语义(dynamic semantic),即运行时才能确定的语义,如除0操作是个运行期的语义错误。
静态语义分析包括声明和类型匹配,类型转换等。比如,将浮点类型表达式赋值给整形表达式时,隐含了一个浮点型到整型的转换过程,语义分析需要完成这个步骤。将浮点类型赋值给一个指针的时候,语义分析过程会检查出类型不匹配,编译器会报错。经过语义分析后,整个语法树的表达式都标识了类型,如果有些类型需要做隐式转换,语义分析过程会在语法树中插入相应的转换节点。经过语义分析阶段后的语法树如图所示:
中间语言生成
现代编译器有多个层次的优化,源码级优化器(source code optimizer)完成源代码级别的优化,如2 + 6表达式会被优化掉,直接计算得到8,更多源码级优化可以参考编译器设计相关的资料。优化之后的语法树如图所示:
直接在语法树上做优化比较困难,源码级优化器先将语法树转换成中间代码(intermediate code),它是语法树的顺序表示,已经很接近目标代码,但是与目标机器和运行时环境无关,如它不包含数据尺寸、变量地址寄存器的名字等。
中间代码有多种类型,比较常见的有三地址码(Three-adress Code)和P代码(P-Code)。gcc使用GIMPLE的三地址表示中间代码[8],最基本的三地址码是这样的:
1 | x = y op z |
因为一个三地址语句中有三个变量地址,三地址码得名于此。这个三地址码表示将变量y和z进行op操作以后赋值给x。上面的语法树翻译成三地址码是这样的:
1 | t1 = 2 + 6 |
这里利用了几个临时变量t1、t2、t3,在三代码的基础进行性优化,可以将t1计算出来,将后面的t1都替换掉:
1 | t2 = index + 4 |
这里t3临时变量也可以优化掉:
1 | t2 = index + 4 |
中间代码使得编译器被分为前端和后端,编译器的前端负责产生与构建机器无关的中间代码,编译器后端将中间代码转换成目标机器代码。对一些跨平台的编译器而言,可以针对不同的平台使用同一个前端,针对不同机器平台设计不同的后端。
目标代码生成与优化(object code generate & optimize)
生成中间代码之后的编译工作都属于编译器后端,主要包括代码生成器(code generator)和目标代码优化器(target code optimizer)。
代码生成器将中间代码转换为目标机器汇编代码,这个过程依赖于目标机器,不同的目标机器有着不同的字长、寄存器、指令等。示例代码生成的x86_64的汇编代码如下所示:
1 | movl %edi, -4(%rbp) |
最后,目标代码优化器对上述目标代码进行优化,这个级别的优化回合目标机器相关,如选择合适的寻址方式、使用位移代替乘法运算、删除多余指令等。源码级优化和目标代码优化,可以参考[9][10]。
汇编(assembly)
汇编器将汇编代码转换成机器可以执行的机器指令,每条汇编语句几乎都对应一条机器指令。所以汇编器的汇编过程相对比较简单,没有语法、语义,也不涉及指令优化,仅仅根据汇编指令和机器指令的对照表一一翻译即可,“汇编”这个名字就源于此。gcc的汇编过程由汇编器as来完成:
1 | # as hello.s -o hello.o |
汇编器输出的目标文件(object file)以.o结尾。
链接(linking)
原始链接的概念在高级编程语言发明之前已经存在。最开始的纸带打孔编码都无需经过编译、汇编过程,而是直接编写的二进制机器码在计算机上运行。
就在打孔编码的蛮荒时代也会遇到“软件工程问题”,如在第1条指令和第5条指令之间插入指令,则第5条指令及后面的指令的位置都会相应往后移动,原先指令中存在指向这些调整位置指令的地址就需要调整。若编码工作由多个团队协作,甚至存在跨纸带的地址调整。重新计算各个目标地址的工程称作重定位(relocation)**,最开始这个工作认为完成,不仅枯燥、繁琐,还容易出错。
显然,重定位工作交给程序完成才是最合适的,汇编语言应运而生。汇编语言引入了一套助记符,如跳转指令使用jmp表示,不仅方便程序员阅读代码,还引入了符号(symbol)** 的概念。符号用来表示一个地址,可能是一段子程序,也可能是一个变量的起始地址。
如第1条指令是jmp foo,第5条指令开始的子程序命名为foo。不管foo这个符号所在的地址如何变化,汇编器每次汇编程序时都会重新计算foo符号地址。
有了汇编语言之后,开发效率极大提升,随之软件规模扩大。人们开始考虑将不同功能的代码按照一定的方式组织起来,便于阅读、开发、维护。自然而然,人们按照代码功能或者性质划分,形成了不同的功能模块,模块之间按照层次结构或者其他结构组织起来。程序被分割成不同的模块之后,将不同的模块组合成单一程序的过程称为链接。链接问题归根结底是模块间的通信问题,C程序的模块间通信方式有两种:
- 模块间的函数调用
- 模块间的变量访问
两种方式都是模块间的符号引用,因此链接就是解决模块间的符号引用问题。从原理上讲,链接过程是多模块场景下,对其他符号的地址的引用加以修正。链接过程主要包括了地址和空间分配(Address and Storage Allocation)、符号决议(Symbol Resolution)和重定位(Relocation)等步骤。
地址和空间分配:目标文件中的代码和数据信息以section的方式组织,结果目标文件中代码、数据section由参与链接的目标文件相应的section组成。地址和空间分配是组合成结果目标文件section时考虑其虚拟地址以及存储空间。
符号决议:将符号的引用与符号定义建立关联
重定位:修正符号引用处符号地址,每个要被修正的地方叫做重定位入口(relocation entry)。
链接分为静态链接和动态链接,静态链接的空间分配、符号决议、重定位在编译过程中完成,输出的可执行程序已经确定了所有符号的地址。动态链接的最终符号重定位步骤完成可能发生在可执行程序加载时,或者程序运行时,故得名动态链接。
gcc默认采用动态链接,上述gcc编译过程最后的collect2执行的是链接过程,collect2可以看做是对链接器ld的封装,ld源于binutils项目。可见动态链接也会有ld链接器完成目标文件的组装。
Reference
[1] https://westes.github.io/flex/manual/Format.html#Format
[2] https://westes.github.io/flex/manual/Patterns.html#Patterns
[3] https://tldp.org/HOWTO/GCC-Frontend-HOWTO-3.html
[4] https://pandolia.net/tinyc/ch8_flex.html
[5] https://gcc.gnu.org/install/build.html
[6] https://en.wikipedia.org/wiki/Yacc
[7] https://tomassetti.me/why-you-should-not-use-flex-yacc-and-bison/
[8] https://gcc.gnu.org/wiki/GIMPLE
[9] https://www.geeksforgeeks.org/code-optimization-in-compiler-design/?ref=lbp
[10] https://www.tutorialspoint.com/compiler_design/compiler_design_code_optimization.htm