原文链接:https://preshing.com/20120515/memory-reordering-caught-in-the-act/
用C/C++编写无锁代码时,必须特别注意强制执行正确的内存顺序。否则,可能会发生令人惊讶的事情。
Intel SDM卷3第8.2.3节举了几个例子。这是最简单的例子之一。假设您在内存中保存了两个整数X和Y,初始值都为0。两个并行运行的处理器执行以下机器代码:
这是一个绝佳的例子说明CPU排序(CPU ordering)。每个处理器将1存储到其中一个整数中,然后将另外一个整数加载到寄存器中。
很自然地我们期望:无论哪个处理器先将1写入内存,另一个处理器可以将该值读回来,这意味着我们最终应该得到r1 = 1, r2 = 1,或者两者都有。然而Intel规范表明r1和r2都等于0也是一种合法的结果。
Intel x86/64处理器与大多数处理器系列一样,允许根据某些规则对内存操作的机器指令进行重新排序,只要不改变单个线程的执行结果即可。具体地说,允许每个处理器将其上的内存写操作(store)推迟(delay)到不同位置的内存加载(load)操作之后。每个处理器上的指令可以重排如下: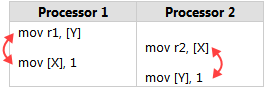
Let’s Make It Happen
眼见为实,我编写了一个小示例程序来展示这种重新排序。你可以在此下载源码。
示例代码包含Win32版本和POSIX版本。它产生两个工作线程,它们无限期地重复图中的例子,而主线程则同步它们的工作并检查每个结果。
下面是第一个工作线程的源代码。X, Y, r1和r2都是全局变量,POSIX信号量用于协调每个循环的开始和结束以及主线程的检查工作。
1 | sem_t beginSema1; |
在每个事务之前添加一个短暂的随机延迟,以错开线程事务开始执行的时间。我们尽量让两个线程的指令执行重叠,随机延迟通过MersenneTwister实现,我们在测量锁竞争以及验证递归互斥量时用到过。
不要被代码中的asm volatile行吓到。这只是一个伪指令,告诉GCC编译器在生成机器代码时不要重排存储和加载。我们可以通过汇编代码验证。如下所示,正如预期的那样,存储和加载按照预期的顺序进行。随后的指令将寄存器eax中的内容写入到全局变量r1中。
1 | $ gcc -O2 -c -S -masm=intel ordering.cpp |
主线程源代码如下所示。它执行所有管理工作。初始化后,它将无限循环,在每次迭代启动线程之前,将X和Y重置为0。
要特别注意:所有对共享内存的写操作都在sem_post之前发生,而所有对共享内存的读操作都在sem_wait之后发生。 与主线程通信时,工作线程赢遵循相同的规则。可以通过信号量让我们在所有平台上支持获取和释放语义(acquire and release semantics)。这样就可以保证X = 0和Y = 0的初始值将完全传播到工作线程,并且r1和r2的结果值也会传播到主线程。换言之,信号量可以防止内存重排,使我们可以完全专注于实验本身!
1 | int main() |
我们看下在CentOS8 AMD Ryzen 5 4600H环境上的运行结果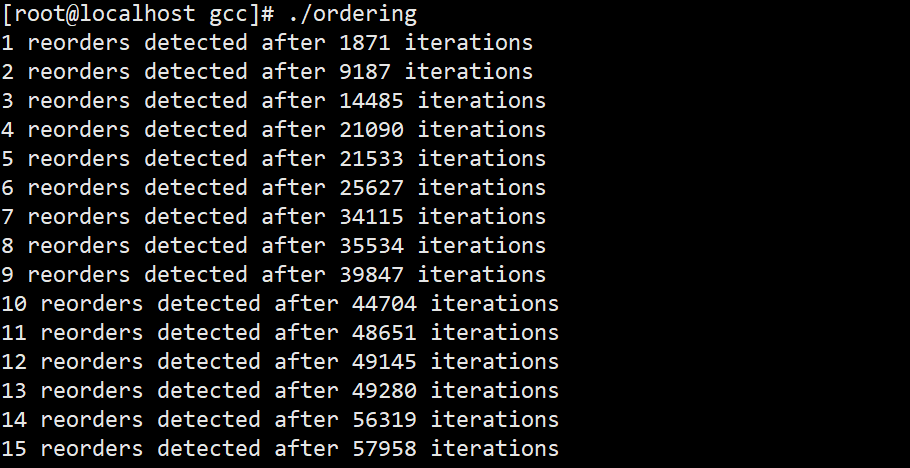
假设您现在想消除内存重排。至少有两个方法可以做到,一种方法是设置线程亲和性,使得两个线程在同一核上工作。没有一种可移植的方法可以设置pthread的亲和性,但在Linux上可以如下完成:
1 | cpu_set_t cpus; |
更改之后,内存重排消失。处理器不会看到自身的操作乱序,即便线程会在任意时间被抢占和重新调度回来。当然将两个线程都绑定到同一CPU core上会导致其他CPU core未被使用。
值得一提的是,我在Playstation 3上编译并运行了这个示例,没有检测到内存重排。这表明(但没有证实)PPU内部的两个硬件线程可以有效地充当单个处理器支持非常细粒度的硬件调度。
使用StoreLoad屏障防止内存重排
此示例中防止内存重排的另一种方法是在两条指令之间引入CPU屏障(CPU barrier)。我们需要StoreLoad屏障防止对load之后的store进行重排。
在x86/64处理器上,没有特定的StoreLoad屏障指令,但是有一些指令可以做到这一点,甚至更多。mfence指令是一个完全的内存屏障,可防止任何类型的内存重新排序。在GCC中可以实现如下:
1 | for (;;) // Loop indefinitely |
同样地,可以通过查看汇编代码验证内存屏障的存在:
1 | ... |
经过这样的修改,内存重排消失了,且允许两个线程在不同的CPU核上运行。
其他硬件平台上的类似指令
mfence并不是x86/64平台上唯一的完全内存屏障的指令。任何锁定的指令(例如xchg)也将充当完全内存屏障-前提是您不使用本示例不使用的SSE指令或write-combined memory。在Visual Studio 2008中,当您使用MemoryBarrier内部函数时,Microsoft C ++编译器会生成xchg指令。mfence指令是x86/64架构独有的。可以通过预处理宏编写更具可移植性的代码。Linux内核将其封装在smp_mb宏中,相关的宏还有smp_rmb和smp_wmb,以及其他架构的实现。例如,在PowerPC上,smp_mb通过sync实现。
不同的CPU系列具有特定的指令强制内存排序,每个编译器通过不同的指令公开它们,每个跨平台项目都实现自己的可移植层……这些都不能简化无锁编程!这也是最近引入了C++ 11标准库的部分原因。这是一种使事情标准化的尝试,目的是使编写可移植的无锁代码更加容易。