在阅读内核源码spin_lock的实现时,发现有大量关于lock-free编程的知识,如smp_cond_load_relaxed、atomic_try_cmpxchg_acquire的实现。延展阅读,发现了这些涉及到memory order、atomic、cache consistency等知识点。经过google,我发现Preshing on Programming这个博客对lock-free的方方面面介绍的较为详细,并且作者将这些知识点在Mintomic(C/C++ lock-free programming API)项目中付诸实践。
原文链接: https://preshing.com/20130618/atomic-vs-non-atomic-operations/
网络上对原子操作的介绍过多集中在原子读-修改-写(RMW)操作上。然而,原子读(atomic load)和写(atomic store)同样重要。在这篇文章中,我将在处理器级别和C/C++语言级别比较原子读和原子写以及它们的非原子操作。在此过程中我们将阐明C++ 11的“数据竞争”(data race)的概念。

在共享内存上的一个操作相对于其他线程而言是单步完成的,那么这个操作就是原子的(atomic)。当在共享变量上执行原子存储(atomic store)时,其他线程无法观察到修改到一半的状态(modification half-complete)。当对共享变量执行原子加载(atomic load)时,它读取在某个时刻出现的完整值(entire value)。非原子加载和存储不能提供这些保证。
没有这些保证,就不可能进行无锁编程(lock-free programming),因为您永远不可能让不同的线程同时操作一个共享变量。我们可以把它制定为一条规则:
任何时候,两个线程并发地操作一个共享变量,其中一个操作执行写操作,两个线程都必须使用原子操作。
如果违反了这一规则,即任何一个线程都使用了非原子操作,那么就会出现C++ 11标准所称的数据竞争(data race,不要与Java的数据竞争概念混淆,这是不同的,是一种更通用的竞争条件)。C++ 11标准并没有告诉你为什么数据竞争是糟糕的,只是存在数据竞争时,会产生一个未定义的行为(1.10.21)。此类数据竞争不佳的真正原因实际上很简单:它们导致读取损坏(torn reads)和写入损坏(torn writes)。
一个内存操作可以是非原子的,因为它使用多条CPU指令;即便是使用单个CPU指令的内存操作也可能是非原子的。亦或您在编写可移植的代码时你无法做出假设认为其实原子操作,则该内存操作有可能也是非原子的。让我们看几个例子。
由于多条CPU指令导致的非原子操作
假设有一个初始值为0的64位全局变量。
1 | uint64_t sharedValue = 0; |
某个时候,你可以为该变量赋64位的数值。
1 | void storeValue() |
使用GCC将此函数编译为32位x86程序,它将生成以下机器代码。
1 | $ gcc -O2 -S -masm=intel test.c |
如您所见,编译器使用两条单独的机器指令实现了64位赋值操作。第一条指令将低32位设置为0x00000002,第二条指令将高32位设置为0x00000001。显然,此赋值操作不是原子的。如果sharedValue被不同的线程并发访问,则可能会出错:
- 线程正在执行
storeValue操作期间的两条mov指令被其他线程抢断,此时共享内存中保留的是0x0000000000000002- 写损坏。此时,如果另一个线程读取sharedValue,它将接收到这个完全错误的值。 - 更糟糕的是,线程正在执行
storeValue操作期间的两条mov指令被其他线程抢断,另外一个线程在第一个线程恢复之前修改了sharedValue,这将导致永久的写损坏:一个线程写入了高32位,另一个线程写入了低32位。 - 在多核环境上,甚至不需要抢占就会导致写损坏。一个核上的线程正在执行
storeValue,同时另一个核上的线程正在读sharedValue,其会看到共享变量被部分修改的状态
并发读`sharedValue``会带来一系列问题:
1 | uint64_t loadValue() |
编译器也使用两条机器指令实现了加载操作:第一个将较低的32位读取到eax中,第二个将较高的32位读取到edx中。在这种情况下,如果对sharedValue的并发存储在两条指令之间变得可见,即使并发存储是原子的,也会导致读取损坏。
上述问题不仅理论上存在。Mintomic的测试套件包括一个称为test_load_store_64_fail的测试用例,其中一个线程使用普通赋值运算符将64位值存储到单个变量,而另一个线程从同一变量重复执行普通读取,以验证每个结果。如预期的那样,在多核x86-32环境上,该测试始终失败。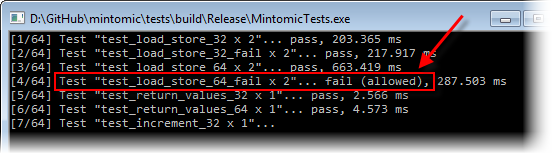
非原子CPU指令
单指令的内存操作也可能是非原子的。例如,ARMv7指令集包含strd指令,该指令将两个32位源寄存器的内容存储到内存中的单个64位值。
1 | strd r0, r1, [r2] |
某些ARMv7处理器上,这条指令不是原子的。当处理器看到这条指令时,它实际上会在幕后执行两个单独的32位存储(A3.5.3)。另一个核上运行的线程可能会观察到写损坏。甚至在单核设备上也可能发生写入中断:在两个内部32位存储之间可能会发生系统中断(例如,用于计划的线程上下文切换)! 在这种情况下,当线程从中断中恢复时,它将再次重新启动strd指令。
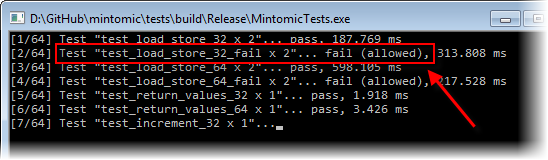
再举一个例子,在x86上,如果内存操作数是自然对齐的,则32位mov指令是原子的,否则是非原子的。换句话说,仅当32位整数位于4的精确倍数的地址上时,原子性才能得到保证。Mintomic的另一个测试用例test_load_store_32_fail可以验证。此测试在x86上一直成功,但如果将sharedInt强制放到未对齐的地址,它将失败。在我的Core 2 Quad Q6600上,当sharedInt越过缓存行边界时,测试失败:
1 | // Force sharedInt to cross a cache line boundary: |
已经介绍了足够多处理器级别的原子性,接下来看看C/C++语言级别的原子性。
假定所有C/C++操作都是非原子的
在C和C++中,所有操作都假定为非原子操作,即便是普通的32位整数赋值。除非编译器或硬件供应商另行指定。
1 | uint32_t foo = 0; |
语言标准并未提及内存操作的原子性。整数赋值也许是原子的,也许不是。由于非原子操作不作任何保证,根据定义,C语言中的普通整数赋值是非原子的。
实际情况下,我们通常对程序运行的目标平台有更多的了解。例如,在所有现代x86,x64,Itanium,SPARC,ARM和PowerPC处理器上,只要目标变量自然对齐,纯32位整数赋值就是原子的。您可以通过查阅处理器手册和/或编译器文档来进行验证。在游戏行业中,我可以告诉您,很多32位整数分配都依赖于此特定保证。
但是,在编写真正的可移植C/C++程序时,长期以来我们遵循“假装除了语言标准告诉我们的知识之外,一无所知”的传统。可移植的C/C++程序应该被设计在过去、现在和想象中的所有可能的计算设备上运行。我倾向于将内存操作想象为在一台摇杆机上进行摇杆,无法得知最终的结果:
在这样的机器上,你肯定不希望在执行普通赋值的同时执行并发读;最终读取的可能是一个完全随机的值。
C++11终于引入了可移植的原子加载和存储:C++11原子库。使用C++11原子库执行的原子加载和存储甚至可以在上述虚拟计算机上工作,即使C++11原子库必须秘密地加互斥锁保证每个操作的原子性。我上个月发布的Mintomic库,该库不支持那么多平台,但可以在多个较老的编译器上运行,是手动优化且可以保证是无锁的。
宽松的原子操作
回顾本文最开始的sharedValue示例。我们将使用Mintomic对其进行重写使其能够在Mintomic支持的所有平台上原子执行所。首先,我们必须将sharedValue声明为Mintomic的原子数据类型。
1 |
|
mint_atomic64_t类型可以保证每个平台上原子访问的正确内存对齐。这很重要,例如,与Xcode 3.2.5捆绑在一起的用于ARM的GCC 4.2编译器不能保证将uint64_t8字节对齐。
在storeValue中,必须执行mint_store_64_relaxed而非执行简单的非原子赋值操作。
1 | void storeValue() |
类似的,loadValue必须调用mint_load_64_relaxed实现。
1 | uint64_t loadValue() |
使用C++ 11的术语,这些函数现在不受数据竞争。并发执行时,无论代码是在ARMv6/ARMv7(Thumb或ARM模式)、x86、x64还是PowerPC上运行,读取或写入都不会被破坏。如果您想知道mint_load_64_relaxed和mint_store_64_relaxed的实现,那么这两个函数都会扩展为x86上的内联cmpxchg8b指令;其他平台查阅Mintomic的实现。
这是用C++11写成的完全一样的东西:
1 |
|
您会注意到,Mintomic和C++ 11示例都使用了宽松的原子操作,各种标识符的_relaxed后缀很明显地展现了这一点。_relaxed后缀提醒您几乎无法保证内存的顺序。
特别地,宽松的原子操作和其之前、之后的指令重排是合法的,这可能是由于编译器的重排(compiler reordering)或者处理器上的内存重排(memory reordering on the processor)。就像非原子操作一样,编译器甚至可以对冗余的宽松原子操作进行优化。在所有情况下,该操作仍然是原子的。
当并发操作共享内存时,即使您已经知道目标平台上的普通加载/存储是原子的,最好始终使用Mintomic或C++ 11原子库函数。原子库功能提醒您共享内存在其他地方会被并发数据访问。
希望您现在可以更清楚地了解,为什么世界上最简单的无锁哈希表使用Mintomic库函数让不同线程同时操作共享内存。


