gzip是一种压缩格式也是类Unix上的文件压缩/解压缩软件,通常指GNU计划的实现,此处gzip代表GNU zip。gzip文件格式在RFC 1952 GZIP file format specification version 4.3中标准化,gzip基于DEFLATE算法实现数据压缩,DEFLATE算法在RFC 1951 DEFLATE Compressed Data Format Specification version 1.3中标准化。
DEFLATE算法基于LZ77算法和Huffman编码实现流数据压缩。LZ77算法是Abraham Lempel和Jacob Ziv于1977年发布的无损数据压缩算法。LZ77算法是字典压缩算法的一种。字典是encoder维护的包含一组字符串的数据结构,字典压缩过程中,encoder将待压缩的文本在字典中搜索匹配字符串,若找到匹配,则将当前待压缩的字符串用字典中匹配字符串的位置索引来替代,达到缩减数据的效果。LZ77算法的字典是encoder之前已经编码的字节序列。
LZ77算法基本原理
LZ77算法利用文本中字符串具有重复的特点,将后续重复出现的字符串使用<length, distance>二元组表示,length表示匹配字符串的长度,distance表示到之前出现的相同字符串的距离。文本中的重复字符串越多、重复字符串长度越长,LZ77算法则会取得更好的压缩效果。
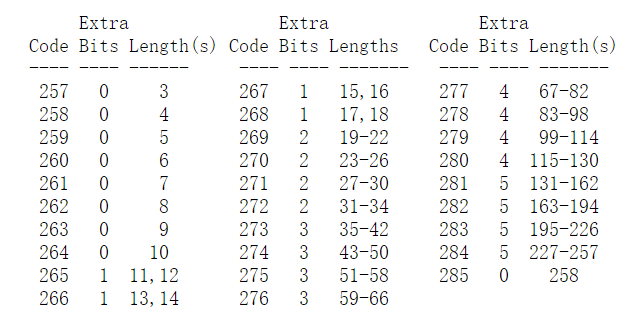
如下图所示,LZ77算法基于滑动窗口实现。滑动窗口包含两部分:前半部分是已经编码的字符流,称为字典或者search buffer;后半部分是待编码的字符流,称为look-ahead buffer。LZ77算法编码look-ahead buffer中的字符时,会在search buffer中寻找最长匹配字符串,若无匹配则直接输出字符(literal),若存在匹配字符串,则将匹配字符串通过<length, distance>编码。DEFLATE算法规定匹配字符串的长度范围是[3, 258]。这个范围是压缩率和算法的时间复杂度之间的平衡。
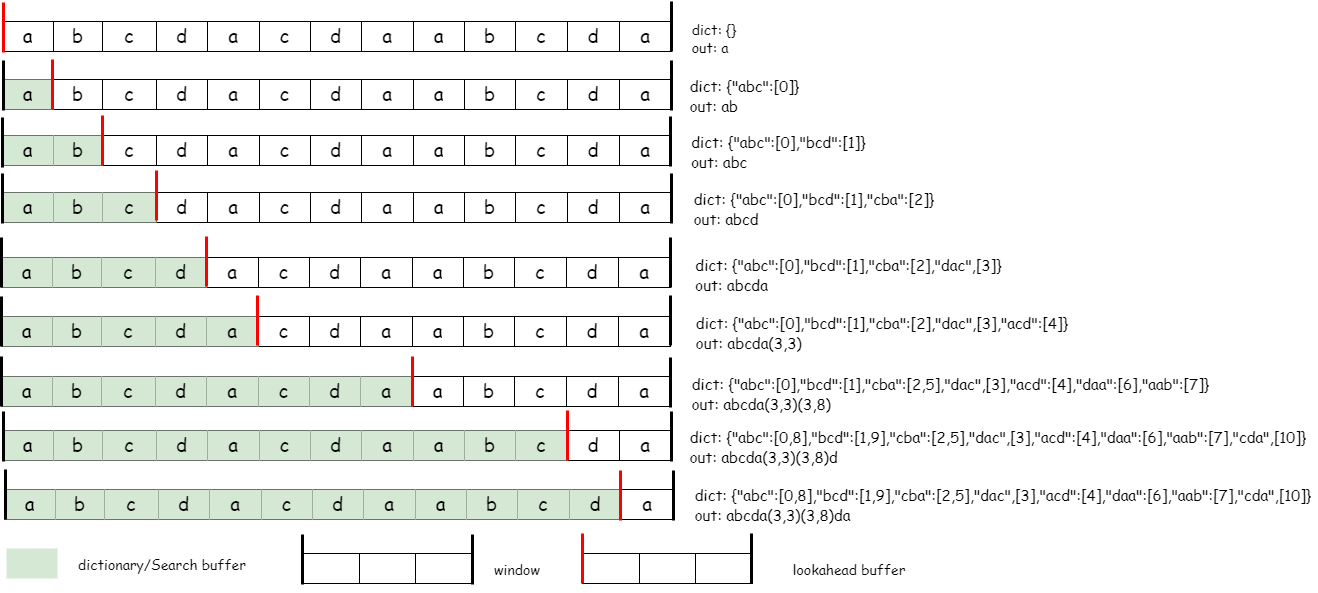
由图可知,LZ77编码的字符流仅包含三种类型的数据:literal、length、distance。实际上,look-ahead buffer长度小于MIN_LOOKAHEAD时,滑动窗口便会向前移动以填充后续数据流从而扩大look-ahead buffer。上图所示look-ahead buffer被匹配完的情况只有在滑动窗口到达字节流末尾,无法向前滑动时出现。fill_window函数表示滑动窗口的实现:
1 |
|
主要解释下几个全局变量:
window_size:滑动窗口大小,默认为64KBlookahead: look-ahead buffer大小strstart: 当前待编码的字符在滑动窗口中的位置
当lookahead < MIN_LOOKAHEAD && !eofile时会调用fill_window更新滑动窗口。会将滑动窗口向前移动WSIZE,并更新match_start、strstart、block_start以及search buffer中的Hash表中hash chain上的索引。DEFLATE算法使用hash表优化匹配字符串的查找,hash表的实现会在最后介绍。最后从字符流中读入数据填充到滑动窗口的后半部分:window+strstart+lookahead起始位置。
惰性匹配(lazy matching)
上图所示的LZ77算法并非最优压缩,当strstart = 8,look-ahead buffer中的内容为abcda时,即便abc在search buffer中能找到匹配字符串,但是紧邻的bcda可以在search buffer中找到更长的匹配串,得到的编码结果是abcda(3,3)a(4,8)。
DEFLATE针对这种情况,设计了惰性匹配(lazy matching)的优化机制:当前匹配的字符串长度为N(N >= MIN_MATCH),会尝试在下一个字符寻找更长的匹配,若在下一个字符能找到更长的匹配(> N),则将前一个字符直接输出到编码流中,即literal;重复这一过程直至找不到更长的字符串匹配,则将前一个字符找到的匹配以<length, distance>二元组输出到编码流中。
1 | local unsigned int near prev_length; |
lazy match的实际实现,我们可以发现:
- 当前字符与匹配字符串的距离不超过MAX_DIST(32768 - 258 - 3 - 1),DEFLATE算法规定最大距离为32768
- 当前字符的最长匹配长度不超过look-ahead buffer长度
match_available = 0表示lazy match过程结束,即当前字符的匹配字符串比前一个字符的匹配字符串要段,重新开始查找最初的匹配字符串。match_available = 1在重新开始lazy match进行第一次匹配时设置。因此,lazy match过程中存在有效的前一个字符匹配的字符串,或者当前字符在search buffer中无匹配的字符串的场景下,match_available都为1。
Hash优化
DEFLATE算法通过链式hash表加速search buffer中的重复字符串查找,链式hash表上存储的是长度为3的字符串的索引。DEFLATE算法的散列函数设计的非常简单、高效:
1 | local unsigned ins_h; /* hash index of string to be inserted */ |

当前字符开始长度为3的字符串的hash key可以通过之前的hash key与当前的字符进行异或运算,在O(1)时间内求得。因此,整个字符流的所有长度为3的字符串的hash key的计算时间复杂度为O(n)。
整个链式hash表的实现也很简单:
head[HASH_SIZE]数组按照hash key索引,相应位置存储的是最近一次计算得到的hash key的字符位置prev[WSIZE]数组存储的是当前字符位置s前一个重复字符串的字符位置
因此遍历hash chain可以用如下循环:
1 | INSERT_STRING(strstart, cur_match); |
fill_window滑动窗口向前移动WSIZE更新hash表时,hash chain中小于WSIZE的索引被更新为NIL,因为这个索引位置的数据已经从滑动窗口移除;其他索引m被更新为m - WSIZE。